


A technical dive into how I made a Final Fantasy XIV proximity voice chat plugin and the learnings I discovered along the way.
Story Time!
It’s no secret I play a lot of Final Fantasy XIV, the online MMORPG, and it’s because I enjoy the raids and I’ve made a lot of good friends on there. So about seven months ago while raiding, a friend asked “What do you think raiding would be like with proximity voice chat in this game?” We talked about all the funny situations that could result, and I figured this was a very interesting project to take on in my free time. By now Dalamud, a very popular open source FFXIV plugin development framework, had plenty of work done to aid new developers make plugins, so I felt like I had the tools to make some sort of proof-of-concept to make this idea happen.
It should be noted that third party tools are prohibited in Square Enix’s terms of service for playing FFXIV. However, given the resources available for plugin development and the potential of the idea, I had to try my hand at making it. We’ll keep it on the down low that this exists, alright?
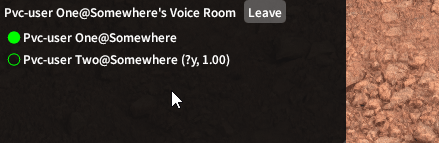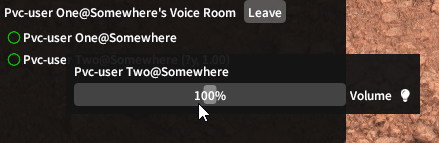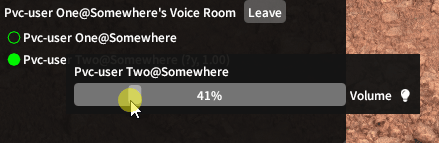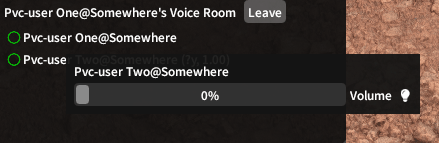
Finding the Tech Stack
A proximity voice chat feature requires two things, proximity detection and a voice chat client. The former is quite simple, Dalamud has a very straightforward API to get the world positions of all loaded players at any given moment. The latter is where things get interesting.
My first idea was to simply piggyback off Discord. Everyone basically already use it for raiding, and it’s already got individual volume control sliders. However, Discord unfortunately does not have any public APIs for external applications to set those volume sliders. Other voice chat clients like Mumble do have a public API for this, but does anyone even use Mumble nowadays? And so, I figured if I can’t use an external voice chat client, then I’ll just embed one directly into the plugin. This is where WebRTC comes in.
Before I jump into explanations, I have to disclaim that my knowledge on all the technologies I’m using is not perfect, and there’s a good chance I might have something wrong or miss a detail. But I’m describing things how I understand them as I learned them for this project.
WebRTC is an open-source project that aims to provide applications with real-time communication (RTC) capabilities that include voice and video transmission. It’s primarily used in web browsers but plenty of wrappers have been written for various environments. The one that I needed is one for .NET, which is what Dalamud runs in. A quick search shows that there’s a couple choices here:
- WebRtc.NET (https://github.com/radioman/WebRtc.NET), which hasn’t been updated in 8 years…
- SIPSorcery (https://github.com/sipsorcery-org/sipsorcery)
- Microsoft MixedReality-WebRTC (https://github.com/microsoft/MixedReality-WebRTC), which was deprecated in 2022
SIPSorcery should be the clear choice here, but I just could not get integration with it to work. After some testing, I went with Microsoft MixedReality-WebRTC as I was able to get it working. To avoid going on a tangent so early, I’ll put the exact issues I faced at the end of this post.
Now the way WebRTC works is that a client first connects to what’s called a “signaling server,” which is a custom-written server that essentially acts like a lobby for clients. When the signaling server receives connect requests from two clients, it acts as a relay for each client to pass data needed to setup a more direct data channel between those clients. This data includes Session Description Protocol (SDP) and Interactive Connectivity Establishment (ICE) information, which allow the data channel to traverse through router firewalls and NAT. Part of this data is each client’s public facing IP address, which can be gathered through a Session Travel Utilities for NAT (STUN) service. With this method, a direct P2P connection is made between clients. However, exposing public IPs between clients like this is a big privacy and security risk. Therefore instead of using STUN, clients can opt to use a Traversal Using Relays around NAT (TURN) server instead, which acts like a relay server between clients, exposing only the TURN server IP to each individual client.
This seems all very complicated but luckily the implementation of establishing a data channel given SDP/ICE data and utilizing a STUN/TURN server are all part of the WebRTC library. The implementation of a basic signaling server can also be found in examples here https://github.com/aljanabim/simple_webrtc_signaling_server and here https://github.com/Meshiest/demo-proximity-voice .
Back to the TURN server, there are online services that sell TURN server capabilities, but I wanted to run as lean as possible, so I turned to open source. Here, there’s two main options:
- Coturn (https://github.com/coturn/coturn)
- Eturnal (https://github.com/processone/eturnal)
Coturn looks to be more popular, but once again the popular choice just did not work for me. So I went with Eturnal and set up a dockerized version in my server box. I should mention that I made heavy use of Docker with all things server-related. It can’t be understated just how helpful Docker is with deployment.
For the other server component, the signaling server, I went with a node.js server that establishes client connections with websockets using the Socket.IO library. Given the widespread use of WebRTC in browsers, it was an easy choice to use the common option of node.js. Socket.IO also has a convenient C# wrapper (https://github.com/doghappy/socket.io-client-csharp) that I can implement into the Dalamud side.
Now that clients can be connected via WebRTC data channels, we’ll need to capture audio data to send. This is done in the Dalamud plugin via the NAudio library, which is a common .NET library used to work with a computer’s audio devices. Data received through the data channels can then be passed to NAudio to playback through an output device.
A quick high-level recap: Clients running the Dalamud plugin connect via websocket to a signaling server. The signaling server then matches clients that should connect to each other, and facilitates sending SDP & ICE data between the them. This data includes the URL of a TURN server which clients use as a relay server for sending and receiving audio data. Once connected, clients capture audio data with NAudio, and send the raw audio bytes through the data channel. Once audio data is received, it’s passed back to NAudio for speaker output.
Working With Audio Data
With the networking stack in place, let’s talk audio data. I didn’t really understand the inner workings of raw audio data before this project, so I’ll take this opportunity to describe how audio data is processed in my plugin. NAudio is the library of choice here, and it handles grabbing the system’s audio devices and performing recording and playback with them. I’m specifically using the WaveInEvent and WaveOutEvent classes as they seem to have the most compatibility across systems.
Let’s walk through making something simple, testing mic playback. To record audio data, a new WaveInEvent class is created with a device number, a WaveFormat, and a buffer duration. The device number can be set to -1 to use the default audio device. A WaveFormat defines how audio data is given as raw data. For compatibility with later features, a WaveFormat with a format tag of Pulse-code modulation (PCM), a sample rate of 48000 Hz, 16 bits per sample, and 1 channel is used. This means when raw audio data comes in, we’ll expect a byte array where every 2 array values should combine together to form one sample, and we’re expecting 48,000 of these samples per second. Next, a buffer duration of 20 milliseconds is used. The higher this number, the higher the latency is from sound input to data output. However, going too low will cause audio data loss, so 20 milliseconds was found to be lowest number without this problem. With the WaveInEvent initialized, StartRecording() is called on it, and WaveInEvent.DataAvailable will begin to emit with data in the format described earlier.
this.audioRecordingSource = new WaveInEvent
{
DeviceNumber = -1,
WaveFormat = new(rate: 48000, bits: 16, channels: 1),
BufferMilliseconds = 20,
};
this.audioRecordingSource.DataAvailable += this.OnAudioSourceDataAvailable;
this.audioRecordingSource.StartRecording();To output this data back to the output device, a new WaveOutEvent class is created with a device number, a desired latency, and a number of buffers. The underlying mechanism here is that the output device will read data placed into the buffers of the WaveOutEvent, so the second and third arguments influence the size and number of these buffers. Going too low on these numbers will also cause audio data loss, so through testing I decided some good numbers were a desired latency of 200 milliseconds and 5 buffers. To initialize the WaveOutEvent, it needs to be given a SampleProvider. A SampleProvider provides readable samples to the WaveOutEvent, but it can also apply audio effects such as adjusting volume and mixing multiple audio channels. These effects can be nested and stacked, which is exactly how the plugin changes the volumes of individual players and then mixes each player’s audio channel together for the output device. Going further up the chain, a SampleProvider needs to read from a WaveProvider. In this case, the only WaveProvider this plugin uses is the BufferedWaveProvider, which can take input audio and store it in buffers to be read, in a very similar manner to the WaveOutEvent.
With the parts described, the full path of the audio data for mic playback is as follows: Audio data is recorded from the WaveInEvent, and then emitted through the DataAvailable event. This data is then passed into a BufferedWaveProvider, which a VolumeSampleProvider wraps around to change the volume. This SampleProvider is initialized into the WaveOutEvent, which reads and clears the buffered audio samples, and sends that output to the device speakers.
Noise suppression
Unless the input device has its own noise suppression (like RTX Voice), we have to perform noise suppression ourselves. To do this, the RNNoise library is used, as it has a convenient .NET wrapper. This library requires an input of float PCM data, so our 16-bit byte data will need to be converted. I found some functions online to do this through this VoiceUtilities.cs script. To apply noise suppression, input audio data from the DataAvailable event is converted, denoised, and then converted back. However, using the functions as given caused really bad audio crackling when speaking loudly. I thought it was something up with the RNNoise library and went down a rabbit hole to recompile the library from source. But it turns out it was due to the conversion from float back to bytes, as the cast from float to short can result in an integer overflow. Despite how simple the problem was, this does give a good example of what malformed audio data sounds like - garbled popping and crackling. The proper conversion function is as follows.
private static void ConvertFloatTo16Bit(float[] input, byte[] output)
{
int sampleIndex = 0, pcmIndex = 0;
while (sampleIndex < input.Length)
{
// Math.Clamp solution found from https://github.com/mumble-voip/mumble/pull/5363
short outsample = (short)Math.Clamp(input[sampleIndex] * short.MaxValue, short.MinValue, short.MaxValue);
output[pcmIndex] = (byte)(outsample & 0xff);
output[pcmIndex + 1] = (byte)((outsample >> 8) & 0xff);
sampleIndex++;
pcmIndex += 2;
}
}Another issue encountered with the denoiser was that whenever the input audio source was paused during voice activity, resuming the input audio source would create a loud popping sound. This was most apparent when using push-to-talk. It turns out that this denoiser library holds previous audio data when denoising current data, so passing in discontinuous audio data causes this audio glitch. The solution was to simply create a new instance of the denoiser when audio input is started or restarted.
Voice activity
A quick tangent - while a voice activity detector doesn’t manipulate voice data, it is very useful information to display in the UI for who is talking. The library used here is the WebRtcVadSharp library. Usage is quite simple, just pass in the incoming raw audio data and the activity detector instance tells you if there’s voice activity or not. One gotcha encountered was that just like the denoiser, an activity detector instance holds transient data, so a single instance cannot be used for multiple audio data streams, or else activity in one stream will appear as activity in all streams. Each voice data channel will need its own activity detector instance.
Networking audio data
To have other clients hear our recorded audio data, we’ll need to send this data through the WebRTC data channels. We must send byte arrays through these channels, but we have the liberty to encode our data however we want into these byte arrays. A recorded audio sample consists of a byte array of raw audio data and an integer of how many bytes should be read from the array, named BytesRecorded. Normally this integer is just the length of the array, but it can be shorter if recording was stopped mid-sample, as the array’s full length is always a constant value based on the WaveFormat the WaveInEvent was initialized with. The raw audio byte array data can easily be copied into our data channel, but we’ll also want to encode the BytesRecorded value. Since this number is provided as a 64-bit integer, we could just add 4 bytes to the start of the data channel byte array, but we don’t want to use more data than necessary given how often audio samples are sent. So, we can calculate the expected value of BytesRecorded using our WaveFormat parameters from earlier (or find it through testing). In our case, the expected BytesRecorded value is 1920. This value is greater than the max value of a byte (255) but much less than the max value of a ushort (65535), a value constructed from 2 bytes. Therefore, we can confidently encode our BytesRecorded data into 2 prepended byte values. The encode and decode functions are as follows.
public static byte[] ConvertAudioSampleToByteArray(WaveInEventArgs args)
{
var newArray = new byte[args.Buffer.Length + sizeof(ushort)];
BinaryPrimitives.WriteUInt16BigEndian(newArray, (ushort)args.BytesRecorded);
args.Buffer.CopyTo(newArray, sizeof(ushort));
return newArray;
}
public static bool TryParseAudioSampleBytes(byte[] bytes, out WaveInEventArgs? args)
{
args = null;
if (bytes.Length < sizeof(ushort))
{
return false;
}
Span<byte> bytesSpan = bytes;
if (!BinaryPrimitives.TryReadUInt16BigEndian(bytesSpan[..sizeof(ushort)], out var bytesRecorded))
{
return false;
}
args = new WaveInEventArgs(bytesSpan[sizeof(ushort)..].ToArray(), bytesRecorded);
return true;
}As a quick note, the endianness of our encoded BytesRecorded value doesn’t matter as we control both the encoding and decoding logic.
When audio data is received through a data channel, it’s decoded and then directly passed into a BufferedWaveProvider for the corresponding client. As described before, all the audio channels get mixed together and then read by the output device. However, this process is not quite as simple as just passing in received audio data and expecting everything to work.
Troubles with latency
When data is passed into a BufferedWaveProvider, it takes time for the output device to read and clear the buffer. If data were to be passed in faster than it can be cleared through playback, then the buffer will gradually fill up. With our previous example of a simple mic playback setup, we can confidently expect audio data to come in at a constant rate and then be played back at a constant rate, so our buffers should be naturally emptied by the time the next batch of audio samples come in. However, when receiving audio data over the Internet, network hiccups can cause a pause in data throughput. These network hiccups could be from any number of reasons, traffic throttling, ISP flow limits, etc.
Let’s walk through an example to see the effects of a network hiccup. Say each audio packet contains 100 ms of audio data and we send these at a constant rate of 10 packets per second. At 5 seconds in, a network hiccup occurs, and pauses data transmission for 500 ms. For 500 ms, the receiving client plays back silence as there is no audio data in its buffer. After this event, all queued packets are transmitted and received at once. The receiving client buffers all 5 packets at once, as well as an extra 6th packet meant for the 5.5 second timestamp. Now, the receiving client starts playing the buffered audio, except it’s playing audio data that was meant for 500 ms ago. New audio data is still coming in at the original rate, and so because playback continues at the same rate, the receiving client has now introduced a permanent 500 ms latency to audio playback.
The upper bound of this latency can be somewhat controlled by the maximum buffer length of a BufferedWaveProvider, as they can be specified to discard old contents if new contents would overflow the buffer. However, this is accepting that any network hiccup will permanently introduce a latency equal to the maximum buffer length. The solution then is to detect when a network hiccup probably occurred, and clear the playback buffer to eliminate all of the old, backed up audio data, effectively resetting buffered latency back to zero.
In our local mic playback case, we’d expect the playback buffer to be almost empty when adding new audio data, and this ensures the lowest possible playback latency. To the same effect, networked playback checks if the playback buffer contents would be too big (and consequently have too much latency) after adding the latest received audio data, and if it is, clears the buffer before adding the new data. I decided to be very aggressive with this “too big” check by using the buffer size of the WaveOutEvent that handles playback as the upper limit. However, through testing, it turns out this was too aggressive, as with too much network latency either through physical distance or server bandwidth load, what would be detected as a network hiccup would occur multiple times a second, causing an unintelligible robotic playback as clearing the playback buffer discontinues the audio stream. I still wanted to retain my aggressive latency-cutting logic, so my solution was to limit the minimum interval of buffer clearing to 5 seconds, with a maximum accepted latency of 1 second. The end result is that under poor network conditions, audio latency could be as bad as 1 second, but only for a maximum of 5 seconds. Any discontinuous cutting that happens every 5 seconds is much more bearable as most of the audio stream now stays intact.
The code ran upon receiving a networked audio packet is as follows.
public void AddPlaybackSample(string channelName, WaveInEventArgs sample)
{
if (this.playbackChannels.TryGetValue(channelName, out var channel))
{
var now = Environment.TickCount;
// If the output device cannot read from the playback buffer as fast as it is filled,
// then the playback buffer can get filled and introduce audio latency.
// This can occur during high system load.
// To remove this latency, we ensure the playback buffer never goes above the expected buffer size,
// calculated from the intended output device latency and buffer count.
if (channel.BufferedWaveProvider.BufferedBytes + sample.BytesRecorded > this.maxPlaybackChannelBufferSize)
{
// However, don't clear too often as this can cause audio "roboting"
var timeSinceLastBufferClear = now - channel.BufferClearedEventTimestampMs;
if (timeSinceLastBufferClear > MinimumBufferClearIntervalMs)
{
channel.BufferedWaveProvider.ClearBuffer();
channel.BufferClearedEventTimestampMs = now;
}
}
channel.BufferedWaveProvider.AddSamples(sample.Buffer, 0, sample.BytesRecorded);
channel.LastSampleAdded = sample;
channel.LastSampleAddedTimestampMs = now;
}
}Conclusion
And that’s about all the technical details I wanted to point out! There’s some monitoring I’ve set up for the signaling server and TURN server using Prometheus and Grafana, but they’re mostly using common setup settings. Maybe I’ll write another post about them if I do more fancy things with them. My work developing this plugin is not done yet, so things might work differently when you read this post. However, all my code’s open source and you can find it on my GitHub, along with instructions for installation if you play FFXIV and want to try it out for yourself. Here’s also a quick demo clip I launched an open-beta version of the plugin with.
FFXIV ProximityVoiceChat open beta is here! I'm doing a sort of soft launch for anyone interested in trying my plugin out. Install instructions are found here: https://t.co/DDMKjJUVfY and I've opened up my dev discord here: https://t.co/ASEduIjUhG pic.twitter.com/AqnBu5lXbk
— Unity XIV (@UnityXIV) February 7, 2025
Thanks for reading! 😄
Appendix
As I mentioned earlier when describing the client tech stack, I ran into a lot of issues trying to settle on a WebRTC library to use, since I wanted to avoid using the deprecated Microsoft MixedReality-WebRTC library if possible. Here’s where I’ll lay out everything that went wrong, for posterity I suppose.
First, SIPSorcery had its own libraries for interfacing with audio devices, using the SDL2 library. When I integrated it, it mostly worked, although for some reason my Steinberg UR12 DAC would randomly stop recording, without throwing any errors. I worked around this by using NVIDIA Broadcast (RTX Voice) as my SDL input source. For the WebRTC part, I had my signaling server set up from mostly copying the implementation in this Javascript-based simple_webrtc_signaling_server repo. When I implemented the WebRTC portion of SIPSorcery, multiple issues came up. The library didn’t seem to generate compatible SDP details to connect to a sample client, and simply initializing an RTCPeerConnection would throw some uncaught Socket exception in Dalamud, despite all my efforts to wrap every asynchronous method in try/catch. Even in a test with two instances of a SIPSorcery client in Dalamud, a peer connection could not be established.
My next line of thinking was to more accurately replicate the sample WebRTC code, so I aimed to run a Nodejs environment in the C# plugin. The options to do this were Node API for .NET and Edge.js, except Edge.js is not actually a viable option since it only works on .NET Framework 4.5 (the plugin is on .NET Core 8.0).
With Node API for .NET, I was able to embed a Nodejs environment into the C# plugin, but there was one massive issue, and it was that the code to load the Nodejs environment could only be ran once per application launch, and any more after that would crash the application. In this case, the application is FFXIV. This limitation would make plugin development hell, as reloading a plugin would lose the reference to the previously instantiated Nodejs environment. So, I looked for ways to keep a reference to this loaded environment. One thought was to make a separate plugin that would never be unloaded and would instantiate the Nodejs environment. However, it ended up proving impossible to access the instantiated class across plugins. Some insane things I tried and learned include:
- You can’t
GCHandle.Alloc& pin classes with reference fields, since those reference fields aren’t pinned and can move around in memory. - The same assembly loaded into different
Assembly.LoadContexts will be treated as different assemblies, meaning you cannot cast a typed class to an object in one context, and then cast it back to the original object in another context. - Dalamud gives a new context for every plugin loaded, so you cannot use Dalamud’s
DataShareto keep an instanced variable reference.
I even considered these ideas, but deemed them way too hard or time consuming to do:
- Build a custom version of Dalamud with the Nodejs environment loader built-in
- Continue down the path of using a separate plugin for the Nodejs environment, but use Reflection and dynamic methods on the Nodejs environment object
- Use aiortc in an embedded Python environment
It was at this point I decided to give Microsoft MixedReality-WebRTC library a try, and felt very embarrassed that the solution was right in front of me this whole time. 😓